纸上烤鱼(ZSKY)DHT磁力链接搜索程序一键安装包
下面的文章来自 :https://lala.im/867.html
本人做了资料整理,因为在文章中,
https://github.com/wenguonideshou/zsky.git
上面的命令已经提示404 ,被原作者删除。
备用命令:
yum -y install git git clone https://gitee.com/xiugan/zsky.gitcd zsky&&sh zsky.sh
为了防止 公共资源库文件被删除,本文存储安装包

ZSKY的作者应该是比较早开始研究DHT磁力链接这块领域的人,我还记得很久前他在Hostloc上发的一系列的磁力链接程序安装和讨论相关的帖子,在我眼里,他是一个热心并且无私奉献的人~
ZSKY是他最近发布的作品,之前我也第一时间知道,但貌似有很多人安装后反应有一些问题,所以我就不急着安装啦,等作者完全都更新调试好后再来安装也不迟,这不一个多月过去了,经常更新的ZSKY现在应该已经很稳定了,所以今天LALA也来尝试搭建一番~
在开始之前我觉得有必要先稍微介绍一下ZSKY这款磁力链接搜索程序的一些特性。首当其冲我要说的是,ZSKY的爬虫只爬取:电影、音乐这些格式的资源,其他资源是不支持爬取的,我个人觉得这个设定有利也有弊,只看各位大佬怎么看了。如果你需要那种爬全网资源没有格式限制的,可以考虑使用SSBC,有关SSBC的安装方法荒岛博客之前也有文章介绍过:
ZSKY相对SSBC来说的话,主要优势在三个方面:
其一:ZSKY的性能是绝对比SSBC要好的,这点毋庸置疑,作者在性能这块做的研究是最大的。
其二:ZSKY的后台功能比SSBC更完善,并且支持一些DIY类的功能,比如添加首页的搜索推荐等等。
其三:ZSKY目前在安装和使用中能遇到的问题基本上都有一个完善的解决方案,不会掉到坑里面去爬不出来~
说了一堆废话,现在来安装吧,安装过程非常简单,作者已经提供了一键安装包,CentOS7系统依次输入下面的命令即可:
yum -y install git git clone https://github.com/wenguonideshou/zsky.gitcd zsky&&sh zsky.sh
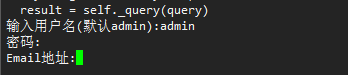
我们需要注意一下的是,在安装的过程中会提示让我们输入一个管理员的账号密码以及邮箱:
在看到如下界面的时候才表面ZSKY是完全安装完毕了:
现在可以打开你的VPS或者服务器的公网IP来访问一下站点了:

在IP后面加上/admin即可访问到ZSKY的后台:
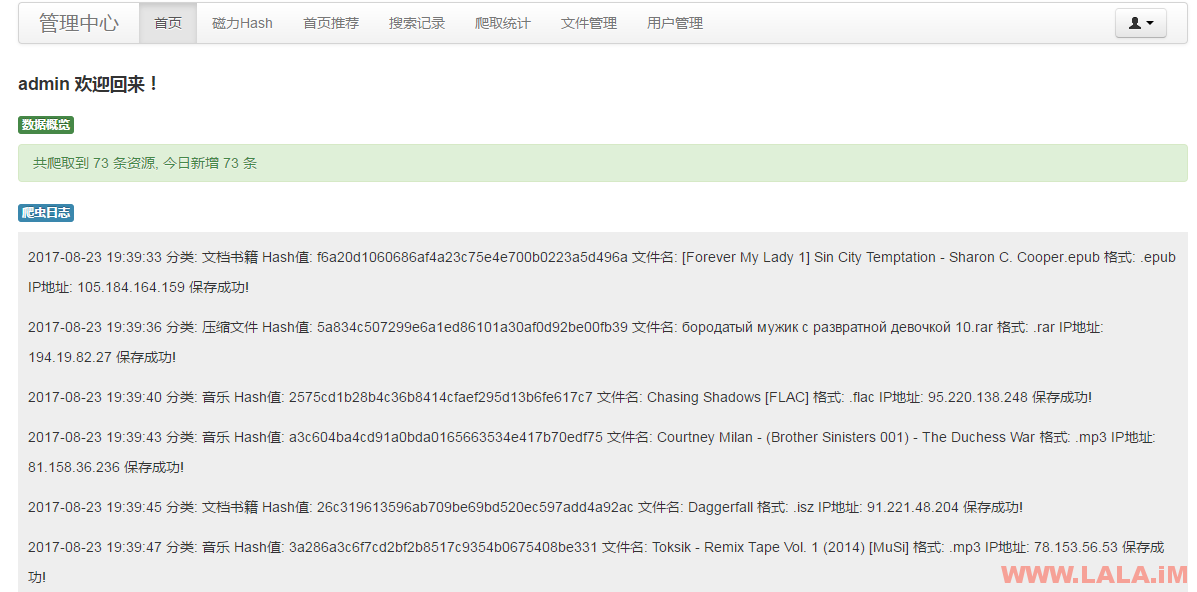
输入我们之前设置的账号和密码登录进去可以看到当前程序的运行状态:
在爬虫爬取了一定量数据并且入库后,我们可以给首页设置一些推荐搜索关键词,设置方法如下:
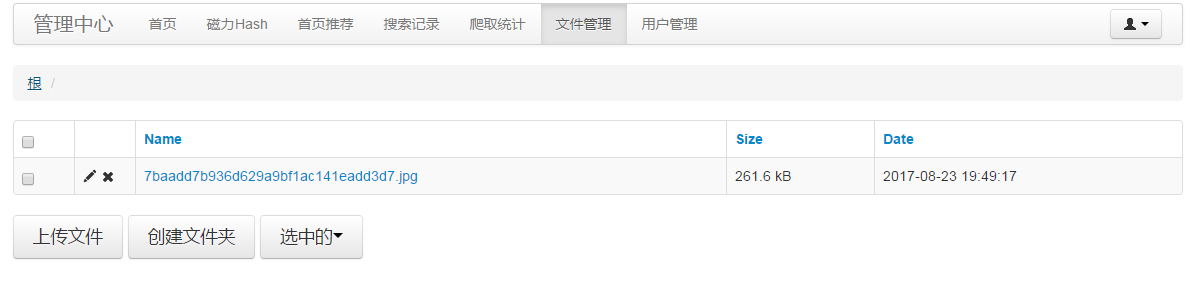
先按照上图点击文件管理,上传一张和关键词相关的图片,接着复制图片地址,点击首页推荐-创建:

在弹出的新窗口中,按如图填写信息:
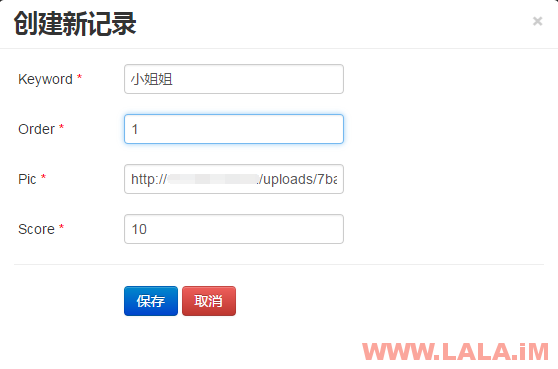
Keyword就是关键词,Order是排序,Pic就填写我们之前上传图片的地址,Score是评分。设置好后刷新一下首页看看变化:
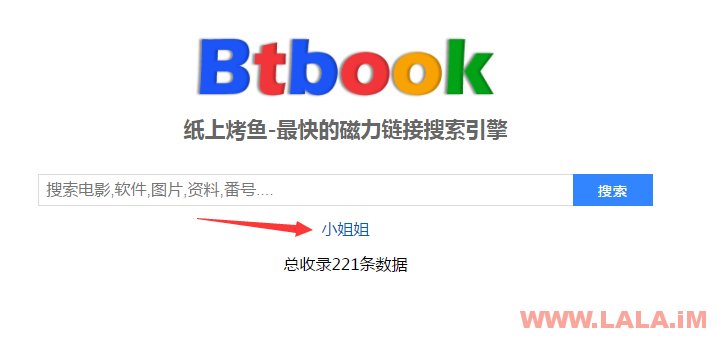
不知道是我哪里设置有问题还是怎么了,图片并不能显示出来,可能还需要更改一下默认模板才行,不过我比较懒就不改啦~
参观一下搜索结果界面:
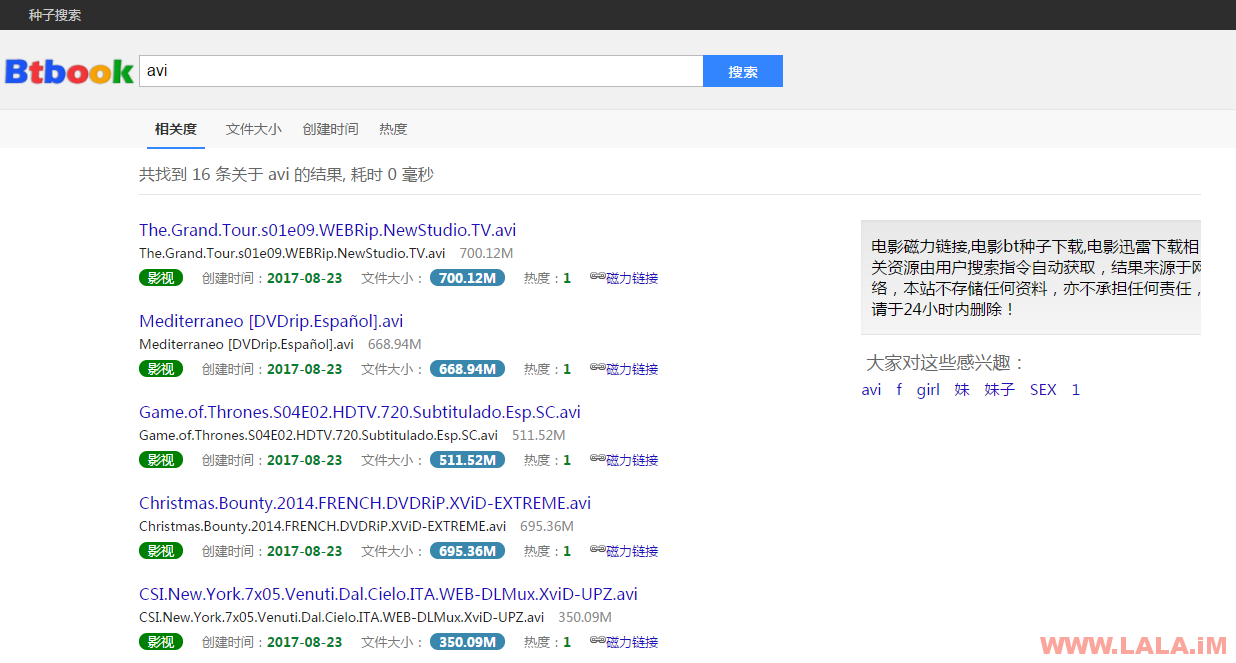
参观一下文件信息界面:
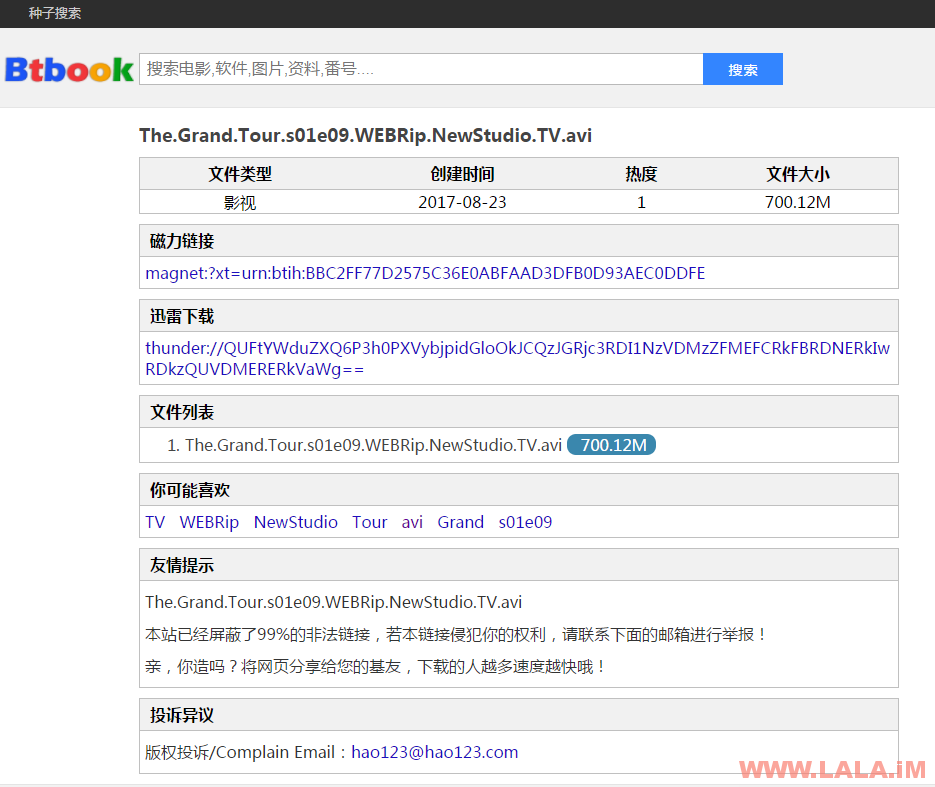
至此整个安装和体验的过程就差不多结束了~
安装脚本只支持Centos7+Python2.7环境
主机配置要求:至少1G内存、至少100G硬盘,至少1G SWAP,具有公网IP的国外主机/服务器
安装脚本执行过程中会提示输入绑定的域名、数据库密码、管理员用户名、密码、邮箱,输入后耐心等待即可访问 http://域名
后台地址 http://域名/admin
安装过程中会提示输入数据库密码。
修改simdht_worker.py里的max_node_qsize的大小调节爬取速度(队列大小)
执行 python manage.py init_db 创建表/平滑升级表结构
执行 python manage.py create_user 创建管理员
执行 python manage.py changepassword 修改管理员密码
执行 systemctl start gunicorn 启动网站
执行 systemctl start mariadb 启动数据库
执行 systemctl status mariadb 查看数据库运行状态
执行 systemctl restart mariadb 重新启动数据库
执行 systemctl status gunicorn 查看gunicorn运行状态
执行 systemctl restart gunicorn 重新启动网站
执行 systemctl restart indexer 手动重新索引
执行 systemctl start searchd 开启搜索进程
执行 systemctl status searchd 查看搜索进程运行状态
执行 systemctl restart searchd 重新启动搜索进程
Q:如何绑定多个域名?
A:在/etc/nginx/nginx/nginx.conf文件内修改,多个域名用空格隔开,修改完成后执行nginx -s reload生效
Q:如何修改站点名?
A:修改manage.py里的常量sitename
Q:如何修改地图里的域名?
A:修改manage.py里的常量domain
Q:如何修改后台地址?
A:修改manage.py中的以下语句中的url=后面的地址: admin = Admin(app,name='管理中心',base_template='admin/my_master.html',index_view=MyAdminIndexView(name='首页',template='admin/index.html',url='/fucku'))
Q:如何屏蔽违禁词
A:在sensitivewords.txt这个文件里面添加违禁词,一行一个,支持.*?等正则符号,添加完成后systemctl restart gunicorn生效
Q:如何实现远程主机反向代理本机的程序?
A:修改本机的/etc/systemd/system/gunicorn.service其中的127.0.0.1:8000修改为0.0.0.0:8000然后执行systemctl daemon-reload,然后执行systemctl restart gunicorn,本机不开启nginx,远程主机开启nginx、配置反向代理、绑定域名即可,nginx的配置文件参考程序内的nginx.conf 。
Q:如何限制/提高爬取速度?
A:修改simdht_worker.py里的max_node_qsize=后面的数字,越大爬取越快,越小爬取越慢
Q:如何修改数据库密码?
A:执行mysqladmin -uroot -p password 123456!@#%^是新密码
Q:修改数据库密码后怎么修改程序里的配置?
A:修改manage.py里的mysql+pymysql://root:密码@127.0.0.1、修改manage.py里的DB_PASS、修改simdht_worker.py里的DB_PASS、修改sphinx.conf里的sql_pass
Q:怎么确定爬虫是在正常运行?
A:执行 ps -ef|grep -v grep|grep simdht 如果有结果说明爬虫正在运行
Q:更新manage.py/模板后怎么立即生效?
A:执行 systemctl restart gunicorn 重启gunicorn
Q:为什么首页统计的数据小于后台的数据?
A:在数据量变大后,索引将占用CPU 100%,非常影响用户访问网站,为了最小程度减小此影响 默认设置为每天早上5点更新索引,你想现在更新爬取结果的话,手动执行索引 systemctl restart indexer ,需要注意的是,数据量越大 索引所耗费时间越长
Q:如何查看索引是否成功?
A:执行 systemctl status indexer 可以看到索引记录
Q:觉得索引速度慢,如何加快?
A:修改sphinx.conf里面的mem_limit = 512M ,根据你的主机的内存使用情况来修改,数值越大索引越快,最大可以设置为2048M
Q:如何确定搜索进程是否正常运行
A:执行 systemctl status searchd ,如果是绿色的running说明搜索进程完全正常
Q:如何备份数据库?
A:执行 mysqldump -uroot -p zsky>/root/zsky.sql 导出数据库 //将提示输入当前密码,数据库导出后存在/root/zsky.sql
Q:数据库备份后,现在重新安装了程序,如何导入旧数据?
A:执行 mysql -uroot -p zsky</root/zsky.sql //假设你的旧数据库文件是/root/zsky.sql,将提示输入当前密码,输入后耐心等待
Q:如何迁移到新主机?
A:备份数据库(方法见上面)→ 程序拷贝到新主机 → 安装程序 → 导入数据库(方法见上面)→ 重新索引
Q:我以前使用的搜片大师/手撕包菜,可以迁移过来吗?
A:程序在开发之初就已经考虑到从这些程序迁移过来的问题,所以你不用担心,完全可以无缝迁移。如果有需求,请加群联系作者付费为你提供服务
Q:网站经常收到版权投诉,有没有好的解决办法?
A:除了删除投诉的影片数据外,你可以使用前端Nginx、后端gunicorn+爬虫+数据库+索引在不同主机上的模式,甚至多前端模式,这样 即使前端被主机商强行封机,也能保证后端数据的安全。如果有需求,请加群联系作者付费为你提供服务。
